新手上路
与很多技术书籍一样,第一章并未涉及到工程上的实现与算法推导,而是对自然语言处理领域概念的罗列与介绍,因此章名取为“新手上路”旨在快速带着读者走进NLP的世界
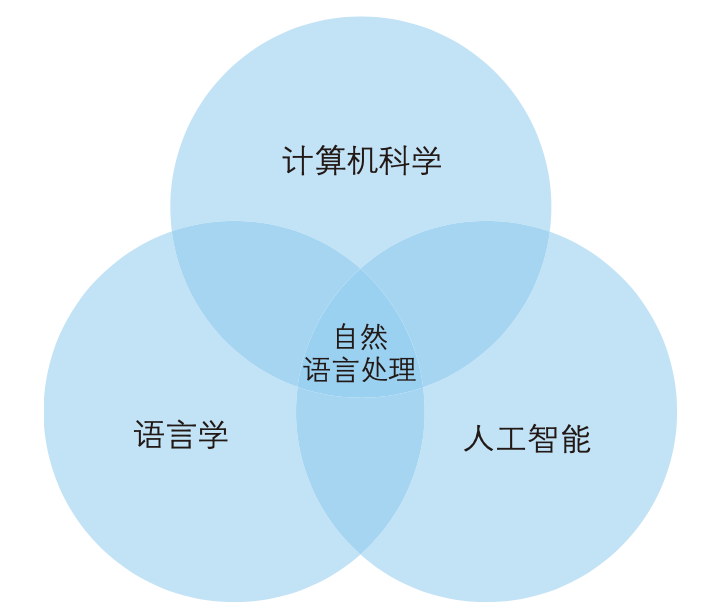
自然语言处理 (Natural Language Processing,NLP)是一门融合了计算机科学、人工智能以及语言学的交叉学科,它们的关系如下图所示
自然语言与编程语言
自然语言——N
编程语言——P
| 区别 | |
|---|---|
| 词汇量 | N的词汇量大,关键词比P丰富;P的关键词有限且确定(void、main) |
| 结构化 | N非结构化,无明确结构关系; P是结构化的,具有显式结构(class/module) |
| 歧义性 | N含有大量歧义(多义词);P无歧义,若两个函数签名一样会触发编译错误 |
| 容错性 | N中一句话错得再离谱,还是可以猜出它的意思;P中若发生拼写或语法错误则会产生bug |
| 易变性 | N变化剧烈,不断创造新词汇;P从旧版本到新版本迭代较缓和(C++ 98->03->11->14) |
| 简略性 | N简洁干练(“老地方见”),交流双方依托经验及对上下文理解使得N不必指示明确 |
总结:相对于编程语言,自然语言复杂的多,计算机理解自然语言也非常困难
自然语言处理的层次
按照处理对象的颗粒度,自然语言处理大致可以分为
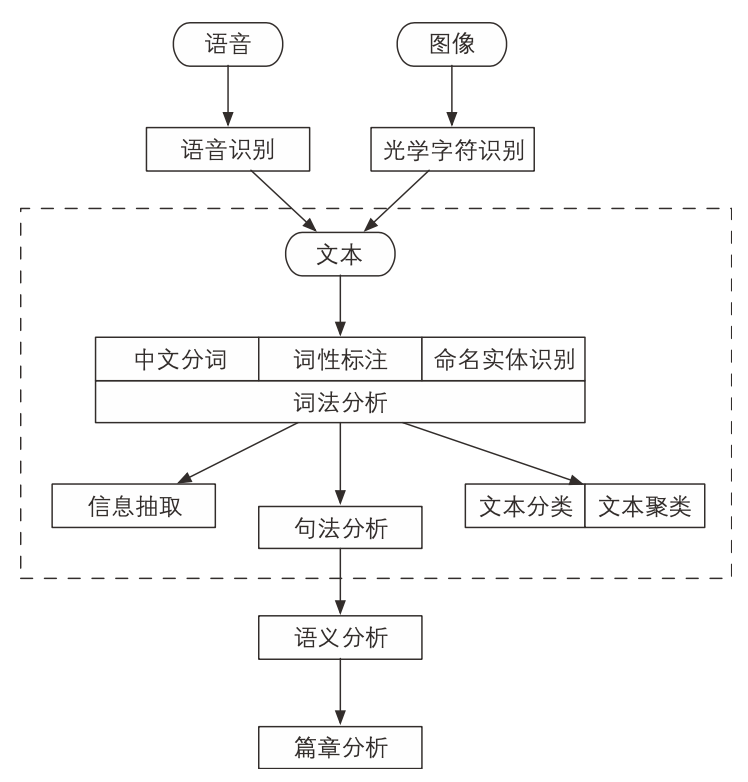
语音、图像和文本
自然语言处理系统的输入源一共有 3 个,即语音、图像与文本。其中,语音和图像一般经过识别后转化为文本,再进行接下来的处理,分别称为语音识别和光学字符识别
中文分词、词性标注和命名实体识别
这 3 个任务都是
围绕词语进行的分析,所以统称词法分析中文分词:将文本分隔为有意义的词语
词性标注:确定每个词语的类别和浅层的歧义消除
命名实体识别:识别出一些较长的专有名词
对中文而言,词法分析常常是后续高级任务的基础,所幸中文词法分析已经比较成熟
信息抽取
词法分析之后,文本已经呈现出部分结构化的趋势。计算机看到的不再是一个超长的字符串,而是有意义的单词列表,并且每个单词还附有自己的词性以及其他标签
根据这些单词与标签,我们可以抽取出一部分有用的信息,从简单的高频词到高级算法提取出的关键词,从公司名称到专业术语
还可以 根据词语之间的统计学信息抽取出关键短语乃至句子,更大颗粒度的文本对用户更加友好
文本分类与聚类
指的是在
文章级别做一系列分析文本分类:把许多文档
分门别类的整理一下(判断一句话褒贬,一封邮件是否是垃圾邮件)文本聚类:把相似的文本归档到一起,或者排除重复的文档,而不关心具体类别
PS:分类有类别目标,类别由人为设定,而聚类没有;前者为监督学习,后者为无监督学习
句法分析
词法分析只能得到零散的词汇信息,计算机不知道
词语之间的关系。通过句法分析可以得到句子的主谓宾结构。比如“查询刘医生主治的内科病人”这句话,通过句法分析后可得

语义分析与篇章分析
相较于句法分析,语义分析侧重语义而非语法,包括:
词义消歧:确定一个词在语境中的含义,而不是简单的词性
语义角色标注:标注句子中的谓语与其他成分的关系
语义依存分析:分析句子中词语之间的语义关系
随着任务的递进,它们的难度也逐步上升,属于较为高级的课题。即便是最前沿的研究, 也尚未达到能够实用的精确程度
其他高级任务
还有许多综合性的任务,与终端应用级产品联系更紧密。比如:
自动问答:根据知识库或文本中的信息直接回答一个问题,比如微软的Cortana和苹果的Siri
自动摘要:为一篇长文档生成简短的摘要
机器翻译:将一句话从一种语言翻译到另一种语言
自然语言处理的流派
基于规则的专家系统
规则,指的是
由专家手工制定的确定性流程。小到程序员日常使用的正则表达式,大到飞机的自动驾驶仪,都是固定的规则系统典型案例有波特词干算法(Porter stemming algorithm)

专家系统难以拓展,容易冲突(比如feed这个单词),需要考虑的兼容性问题很多,非常复杂,维护成本较高
基于统计的学习方法
为了降低对专家的依赖,自适应灵活的语言问题,人们
使用统计方法让计算机自动学习语言,所谓“统计”,指的是在语料库上进行的统计。所谓语料库,指的是人工标注的结构化文本不同于专家系统,基于统计的学习方法以举例子的方式让机器自动学习语言规律。然后机器将这些规律应用到新的、 未知的例子上去。在自然语言处理的语境下,“举例子”就是“制作语料库”
历史
这一小节作者介绍了NLP的发展历史,感兴趣的朋友可以去书本的图灵社区查看,这里列出几个重要节点

20世纪80年代之前的主流方法都是规则系统
20世纪80年代之后,统计模型给人工智能和自然语言处理领域带来了革命性的进展——人们开始标注语料库用于开发和测试NLP模块
特征工程:根据语言学知识为统计模型设计特征模板(将语料表示为方便计算机理解的形式)
2010年后,语料库规模、硬件计算力都得到了很大提升,神经网络得以广泛应用,并冠以“深度学习”的新术语,
它不再依赖专家制定特征模板,而能够自动学习原始数据的抽象表示规则与统计
纯粹的规则系统日渐式微,取而代之的是基于统计的系统,但实际工程中语言学知识的作用有两方面
- 帮助我们设计更简洁、高效的特征模板
- 在语料库建设中发挥作用
实际运行的系统在预处理和后处理的部分依然会用到一些手写规则
传统方法与深度学习
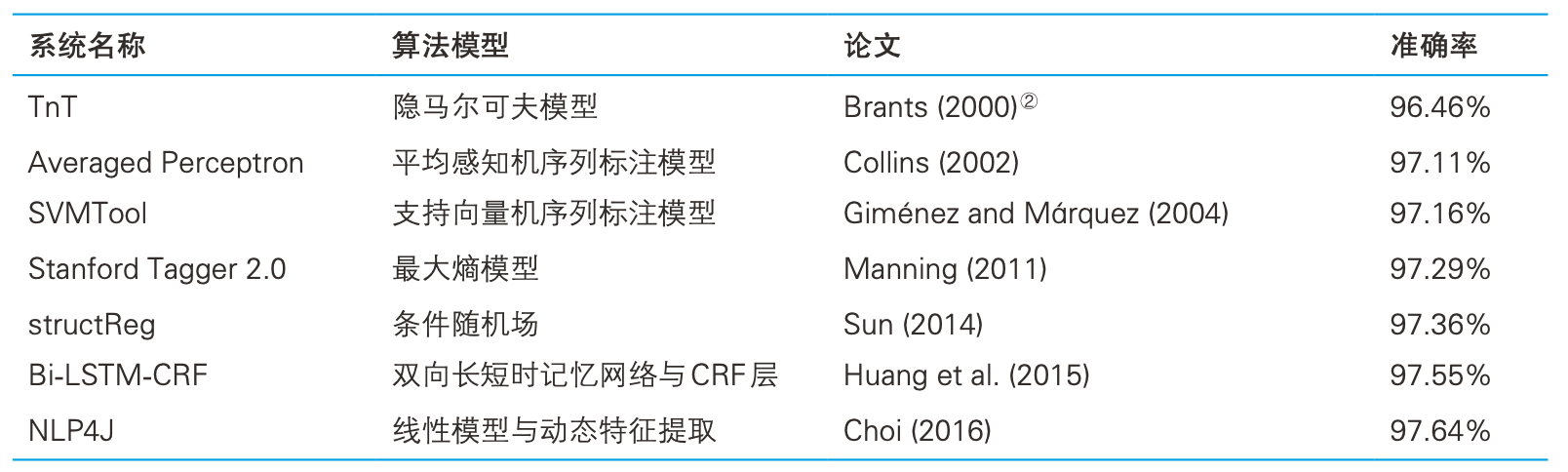
深度学习在CV领域取得耀眼的成绩,但在NLP领域的基础任务上发力并不大
词性标注准确率排行榜
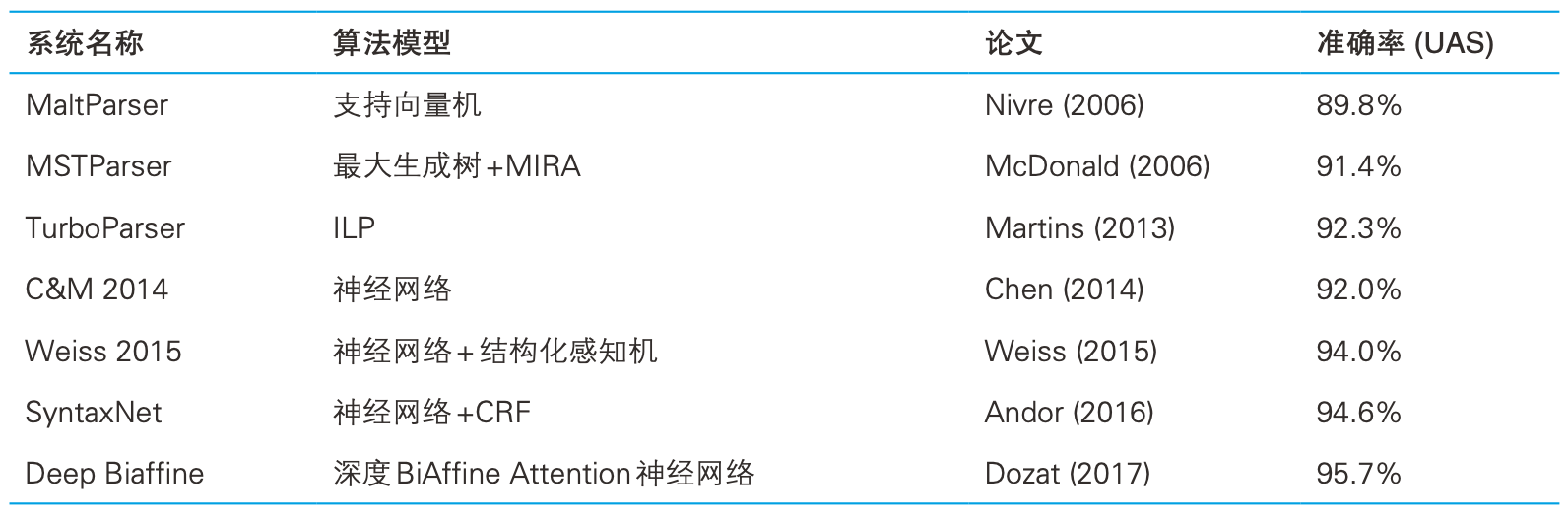
句法分析准确率排行榜
另外,深度学习涉及大量矩阵运算,需要特殊计算硬件(GPU、TPU等)的加速,对硬件需求较高
无论是传统模型还是神经网络,它们都属于机器学习的范畴。掌握传统方法,不仅可以解决计算资源受限时的工程问题,还可以为将来挑战深度学习打下坚实的基础
机器学习
什么是机器学习
美国工程院院士Tom Mitchell给过一个明确的定义
机器学习指的是计算机通过某项任务的经验数据提高了在该项任务上的能力
机器学习是让机器学会算法的算法,可以称作为元算法,它指导机器自动学习出另一个算法,通常称被学习的算法为模型
模型
模型是
对现实问题的数学抽象,由一个假设函数以及一系列参数构成假设中国人名由函数$ f(\boldsymbol x) $输出的符号决定,我们要预测人民对应的性别,负数表示女性,非负数表示男性
其中$\boldsymbol w$和$b$是函数的参数,那么模型就是
包括参数在内的整个函数。而$\boldsymbol x$是函数的自变量,是一个特征向量,用于表示一个对象的特征特征
指的是事物的特点转化的数值,比如牛的特征是 3 条腿、0双翅膀,而鸟的特征是2条腿、1双翅膀。
对于一个中国人名,姓氏与性别无关。有一些特殊的字(壮、雁、 健、强)是男性常用的,而另一些(丽、燕、冰、雪)则是女性常用的,还有一些(文、海、 宝、玉)则是男女通用的。把人名表示为计算机可以理解的形式,
一个名字是否含有这些字就成了最容易想到的特征对于“沈雁冰”(茅盾)这个名字来说,它的特征值可以表示为

1表示含有该字,0则没有。即二维特征向量$ \boldsymbol x^{(1)} $ = [1, 1],模型参数中的权重向量也是二维的:$\boldsymbol w$ = [$w_1$, $w_2$],此时可根据假设函数$f(\boldsymbol x^{(1)}) = w_1 \boldsymbol x_1^ {(1)} + w_2 \boldsymbol x_2^{(1)} + b = w_1 + w_2 + b$是否大于0判断这个名字是否属于男性
可以通过改变特征向量对应的权重来改变最后的结果。另外特征越多,参数就越多,模型也越复杂。模型的复杂度应与数据集相匹配
数据集
供机器学习算法学习的“例子”1称为数据集,一般也称为样本集。在NLP领域中数据集称作语料库
机器学习领域常用数据集

监督学习
如果把数据集比作供机器学习算法学习的习题集,那么监督学习所用的数据集就是有答案的习题集
监督学习算法让机器先做一遍题,然后与标准答案作比较,最后根据误差纠正模型的错误
在上面性别识别的例子中,数据集可表示为($\boldsymbol x^{(i)}, y^{(i)}$),$y^{(i)} \in $ {+1, -1},±1分别代表男女
当答案是男性,而预测结果是女性,即$f(\boldsymbol x)$为负数,只需将$\boldsymbol x_i$对应的权重$w_i$增加即可让函数值从负数变为非负数
这种在有标签的数据集上迭代学习的过程称为训练,训练用到的数据集称作训练。训练的结果是一系列参数(特征权重)或模型。利用模型,为任意一个姓名计算一个值,如果非负则给出男性的结论,否则给出女性的结论。这个过程称为预测
监督学习的流程
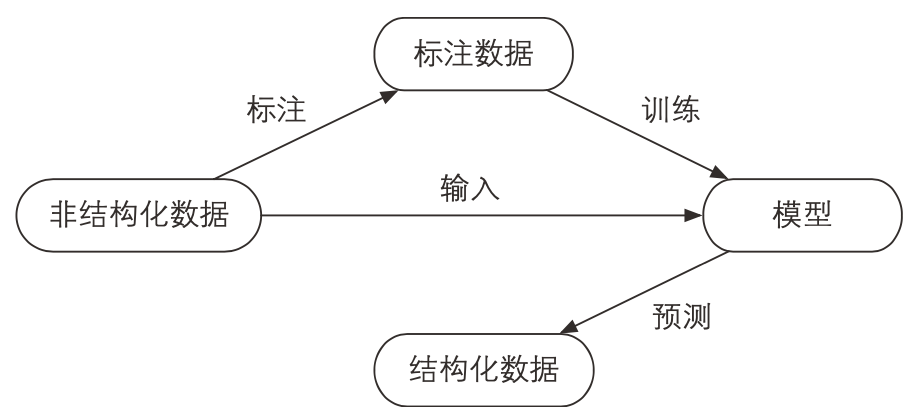
note:非结构化数据即未加标签的数据
无监督学习
习题集只有习题没有答案,即机器学习的数据集没有标签,机器只能发现样本之间的联系而无法学习样本与答案之间的关联。典型的无监督学习有- 聚类:概念参照1.2节中的文本聚类
- 降维:将样本点从高位空间变换到低维空间的过程。中心思想是降维后尽量不损失信息,或者说
让样本在低维空间中每个维度上的方差都尽量大,即保留能体现样本差异度大的维度,去除差异度小的维度
其他典型机器学习算法
- 半监督学习:如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用来
扩充训练集 - 强化学习:现实世界中的事物之间往往有很长的因果链:我们要正确地执行一系列彼此关联的决策,才能得到最终的成果。这类问题往往需要
一边预测,一边根据环境的反馈规划下次决策。常见应用有:自动驾驶、电子竞技和问答系统。
- 半监督学习:如果我们训练多个模型,然后对同一个实例执行预测,会得到多个结果。如果这些结果多数一致,则可以将该实例和结果放到一起作为新的训练样本,用来
1. 参考1.3节自然语言处理的流派中的基于统计的学习方法 ↩
语料库
语料库作为自然语言处理领域中的数据集,是我们教机器理解语言不可或缺的习题集
中文分词语料库
指的是
由人工正确切分后的句子集合。著名的有1998年《人民日报》语料库词性标注语料库
指的是
切分并为每个词语指定一个词性的语料。《人民日报》语料库一共含有43种词性,这个集合称作词性标注集,其中的一句样例为: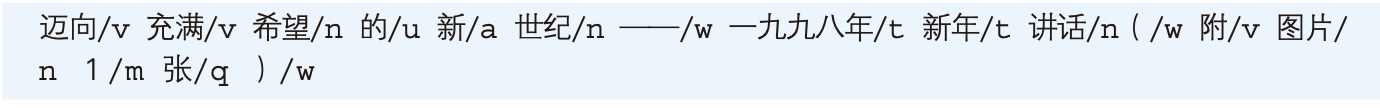
每个单词后面用斜杠隔开的就是词性标签
命名实体识别语料库
这种语料库人工
标注了文本内部制作者关心的实体名词以及实体类别。比如《人民日报》语料库中一共含有人名、地名和机构名3种命名实体:
句法分析语料库
每个句子都经过了
分词、词性标注和句法标注。汉语中常用的句法分析语料库有CTB(Chinese Treebank,中文树库)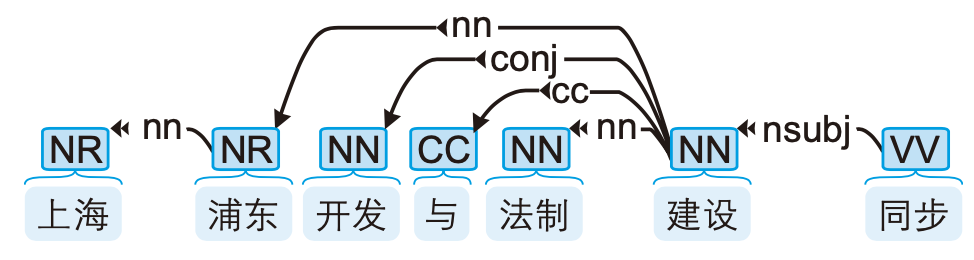
中文单词上面的英文标签表示词性,而箭头表示有语法联系的两个单词,具体是何种联系由箭头上的标签表示
文本分类语料库
指的是
人工标注了所属分类的文章构成的语料库。数据量很大,以著名的搜狗文本分类语料库为例,一共包含汽车、财经、IT、健康、体育、旅游、教育、招聘、文化、军事10个类别,每个类别下含有8000篇新闻,每篇新闻大约数百字
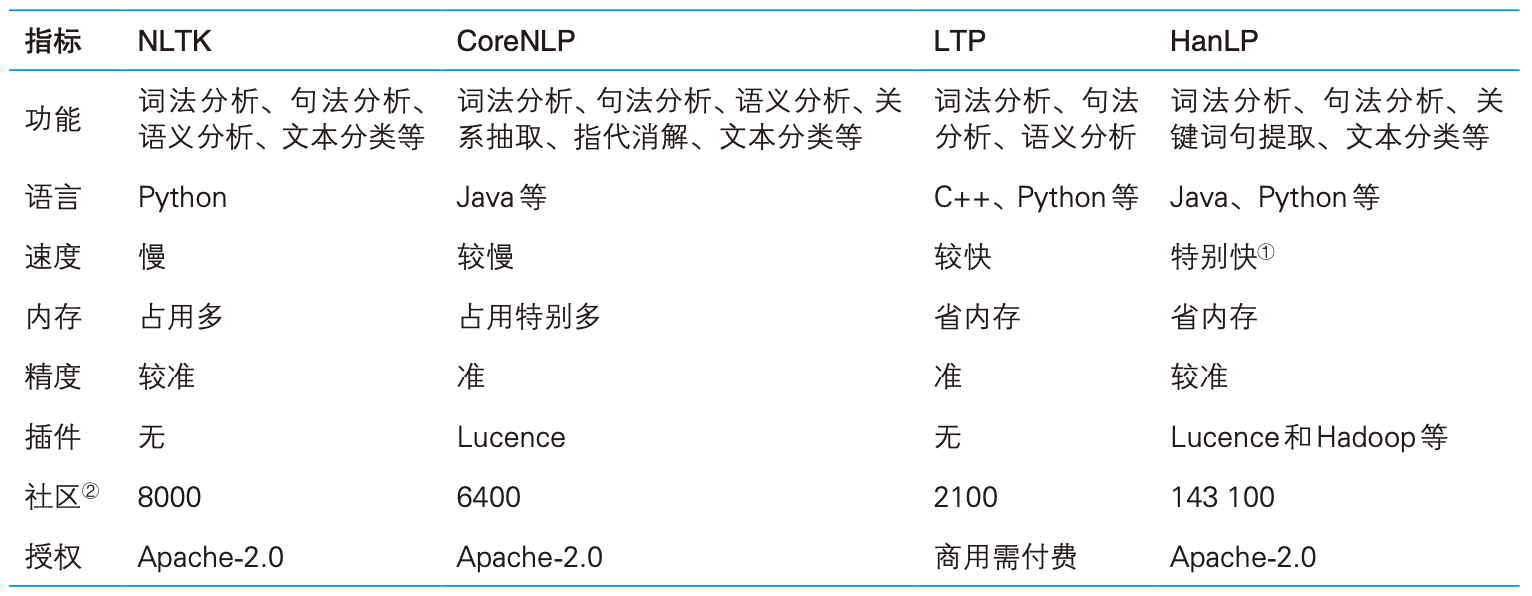
开源工具
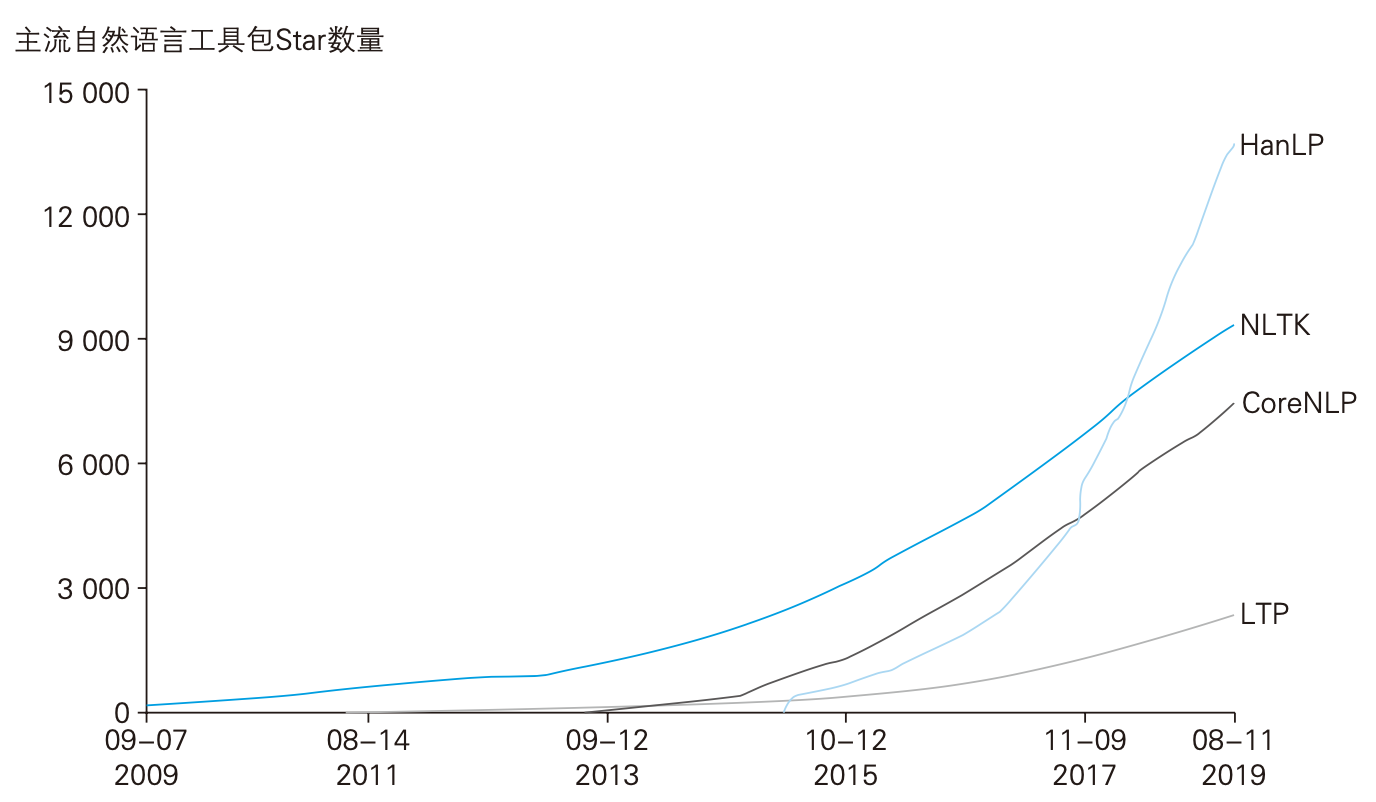
常用的NLP工具有教学常用的NLTK、斯坦福大学开发的CoreNLP,以及国内哈工大开发的LTP、本书作者何晗开发的HanLP
主流NLP工具比较
HanLP Python 接口
HanLP主项目采用Java开发,书上提供了Python和Java两个版本的代码,但因为我习惯用的Python,所以涉及到双代码的地方博客中只选取Python部分讲解。对Java版本代码感兴趣的朋友可以去书中获取或者直接到作者的github上查阅相关代码
HanLP的Python接口由pyhanlp包提供,其安装只需一句命令:
1 | % pip install pyhanlp |
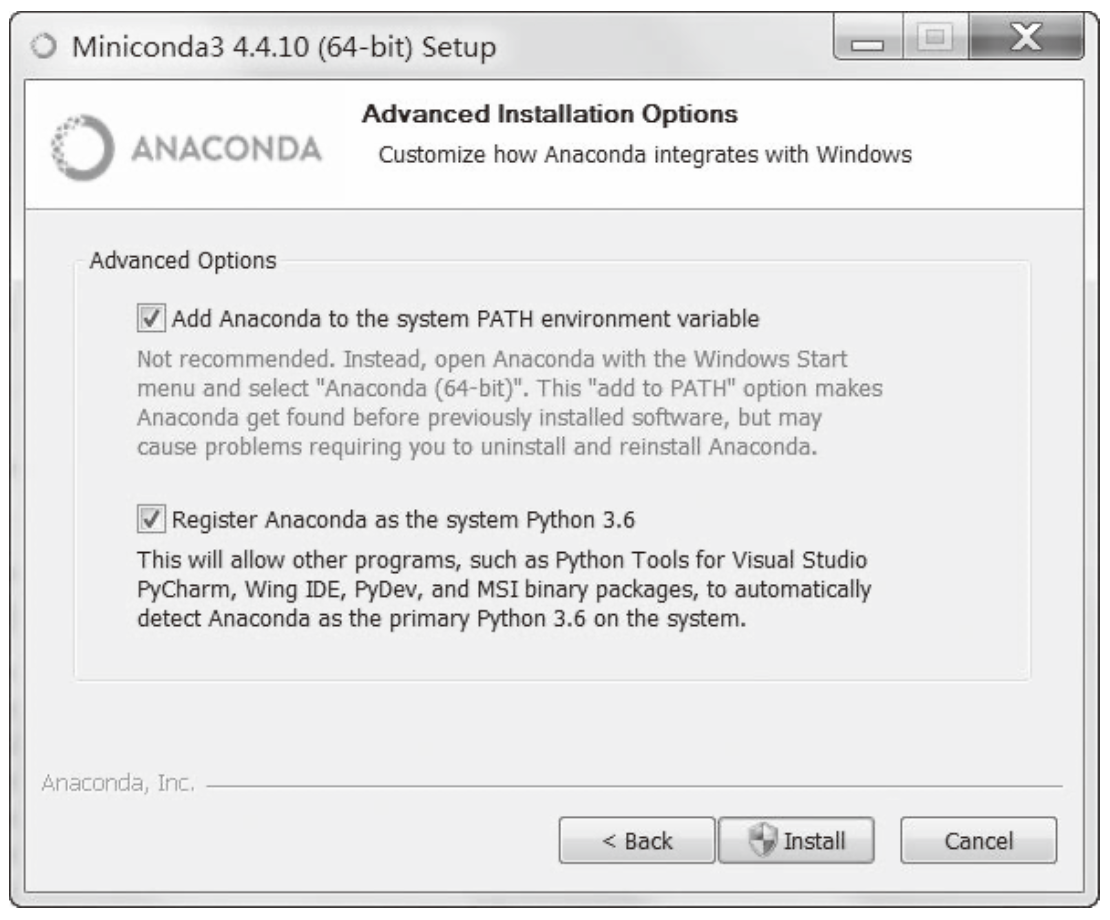
这个包依赖Java和JPype。Windows用户如果遇到如下错误:

既可以按提示安装Visual C++,也可以安装更轻量级的Miniconda。Miniconda是Python语言的开源发行版,提供更方便的包管理。安装时请勾选下图所示的两个复选框
然后执行如下命令:
1 | % conda install -c conda-forge jpype1 |
如果遇到Java相关的问题:

请安装Java运行环境(推荐JDK8以上版本),如果发生其他错误,欢迎前往项目讨论区汇报问题
mac用户如遇到问题可以参考我的这篇文章:谈谈mac python3.7搭建HanLP环境时遇到的坑
测试
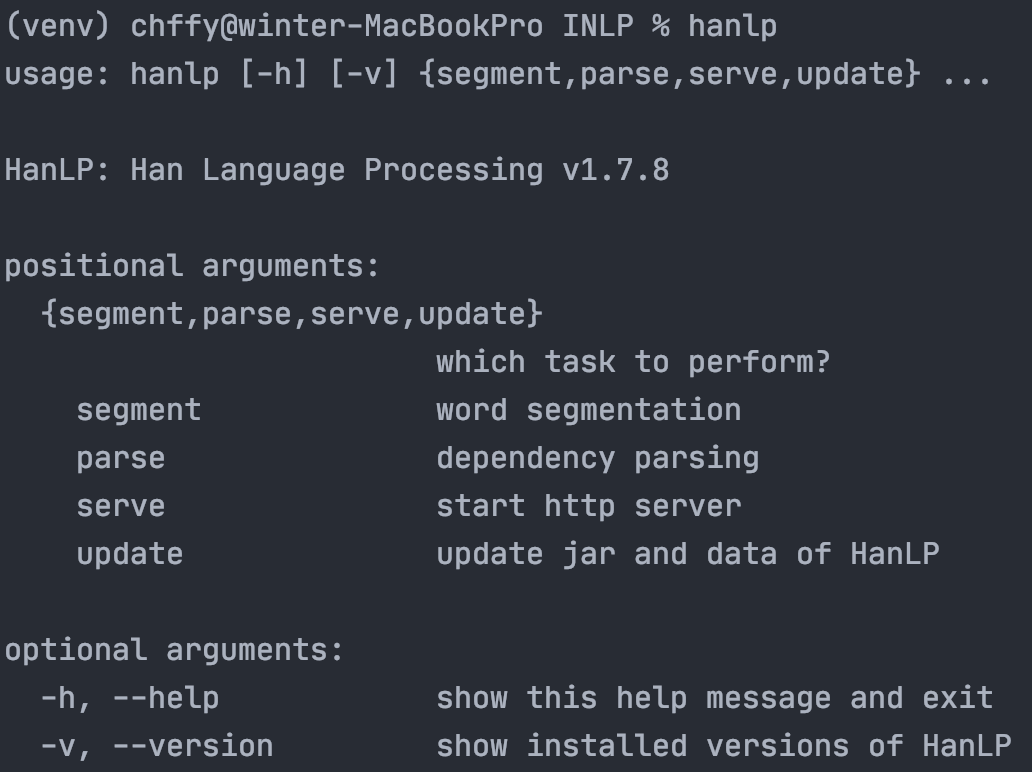
分词

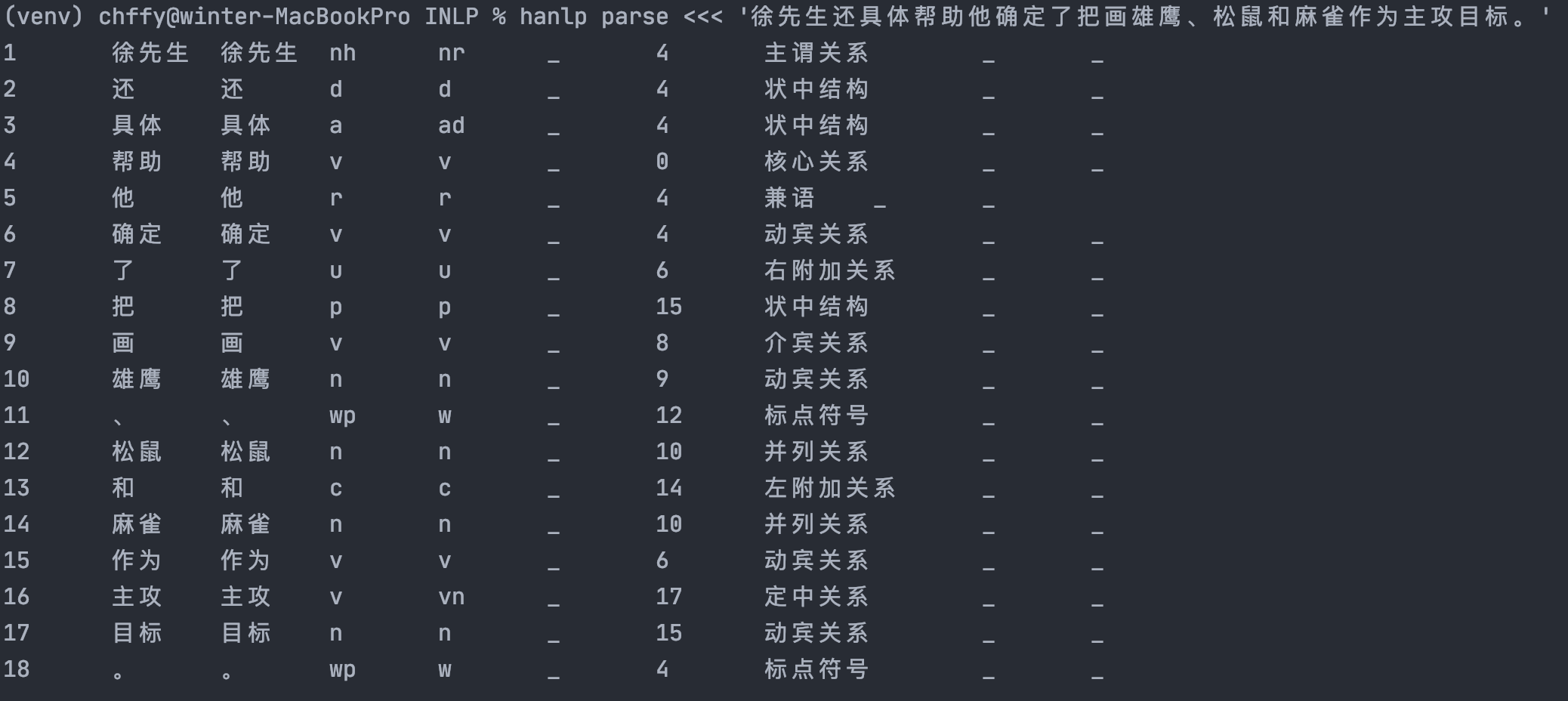
句法分析
《自然语言处理入门》持续更新中
戳 -> 目录、资源汇总页查看其他章节

